
1.벡터(vector) 자료
[1] c() 함수 이용
R에서 기본적인 방법은 함수 “c()”를 이용하는 것이다. 이 함수의 괄호 내에 자료를 나열함으로써 자료를 생성
c(자료 나열)
| > x=c(1, 3, 0.5, 5) #수치 자료 벡터 > x [1] 1.0 3.0 0.5 5.0 > s=c('Kim', 'Lee', 'Park') #문자 자료 벡터 > s [1] "Kim" "Lee" "Park" |
변수 x에는 수치 자료만, 변수 s에는 문자열 자료를 생성하여 할당
| > x=c(1,3,0.5,5) > c(x, c(0,1)) [1] 1.0 3.0 0.5 5.0 0.0 1.0 > s=c(s, 'Choi', 'Lee') > s [1] "Kim" "Lee" "Park" "Choi" "Lee" |
원소의 이름과 함께 입력하고자 할 때는 이름에 자료를 할당하여 입력한다.
| > x=c(x1=1, x2=2, x3=0) > x x1 x2 x3 1 2 0 |
위 결과의 첫 줄은 원소들의 “names”라 한다. 위 결과를 얻는 다른 방법으로 names() 함수를 사용하는 방법이 있다.
| > x=c(1,2,0) > names(x)=c('x1','x2','x3') > x x1 x2 x3 1 2 0 |
수치와 문자자료를 함께 생성하면 모두 문자자료로 취급한다는 점을 유의하자.
| > t=c('Kim',20, 'Lee', 21, 'Park', 25) > t [1] "Kim" "20" "Lee" "21" "Park" "25" |
[2] 콜론 “:” 이용
1씩 증가하는 자료 열을 생성하고자 할 때 “:”을 사용하면 편리하다.
초기값 : 최종값
예를 들어 1부터 10까지의 정수 열과 –2부터 2까지의 정수 열을 생성하고 한다면, 아래와 같이 처리할 수 있다.
| > x=1:10; y=-2:2 > x; y [1] 1 2 3 4 5 6 7 8 9 10 [1] -2 -1 0 1 2 |
만약 0.5부터 4.8 사이에서 1씩 증가하는 수열을 만들고자 한다
| > x=0.5:4.8 > x [1] 0.5 1.5 2.5 3.5 4.5 |
[3] seq() 함수 이용
“:”은 1씩 증가하는 수열을 생성한다. 그런데 예를 들어 0.2 씩 증가하는 수열을 만들려면 “seq()” 함수를 이용해야 한다.
seq(초기값, 최종값, by=증가값) 및 seq(초기값, 최종값, length=길이)
0.5부터 4.8까지 0.2 씩 증가하는 수열을 만들어 보자.
| > x=seq(0.5, 4.8, by=0.2) > x [1] 0.5 0.7 0.9 1.1 1.3 1.5 1.7 1.9 2.1 2.3 2.5 [12] 2.7 2.9 3.1 3.3 3.5 3.7 3.9 4.1 4.3 4.5 4.7 |
증가치로서 음수를 사용할 수 있다. 예를 들어 2에서 1까지 0.1씩 감소하는 수열을 만들어 보자.
| > x=seq(2.0, 1.0, by=-0.1) > x [1] 2.0 1.9 1.8 1.7 1.6 1.5 1.4 1.3 1.2 1.1 1.0 |
초기치와 최종치 사이를 n 등분하여 수열을 생성할 때는 옵션 "length=n"을 사용한다. 예를 들어 1부터 10 사이를 5등분한 자료를 생성해 보자.
| > seq(1, 10, length=5) [1] 1.00 3.25 5.50 7.75 10.00 |
[4] rep() 함수
이 함수는 어떤 자료열을 반복해서 생성한다. 이 함수의 간략한 사용형식은 다음과 같다.
rep(자료벡터, times=n) 혹은 rep(자료벡터, n)
| > rep(c(1,2),times=3) [1] 1 2 1 2 1 2 > x=c(1,2); rep(x, 3) [1] 1 2 1 2 1 2 > rep('Hi! ', 3) [1] "Hi! " "Hi! " "Hi! " |
만약 times를 생략하면, times=1로 간주한다.
[5] paste() 함수
이 함수는 문자열들을 결합하여 새로운 문자열 자료를 생성한다.
paste(문자열, 문자열, …, 문자열, sep=‘구분자’)
| > paste('Hi,','my', 'R!', sep=' ') [1] "Hi, my R!" |
3개의 문자열이 빈칸의 구분자로 결합하고 있다.
수치 열과 결합하여 연속되는 넘버링을 하는 경우에도 유용하다.
| > paste('X', 1:5, sep='') [1] "X1" "X2" "X3" "X4" "X5" |
구분자를 빈칸 없이 정하였다. 한편, 수치 열 1:5 입력되었지만 “자료형의 우선순위”에 의해 문자열로 바뀐다는 점을 유의하자.
paste0() 함수를 이용하면 구분자를 빈칸 없음으로 간주한다.
| > paste0('X', 1:5) [1] "X1" "X2" "X3" "X4" "X5" |
[6] scan() 함수
이 함수는 콘솔을 통해 자료를 순차적으로 입력하거나, 자료 파일을 읽어드리는 함수이다. 이 함수의 용법과 기능은 매우 광범위하므로 자세한 내용은 나중에 다루도록 하고, 여기서는 간단한 용법만 소개한다.
사용 형식은
scan(), scan(what="")
수치자료를 입력할 경우
| > x=scan() 1: 2 2: 0 3: -1 4: #여기서 엔터키 두 번 입력 Read 3 items > x [1] 2 0 -1 |
※자료 입력을 마치려면 엔터키를 두 번 친다.
문자자료를 입력할 경우
| > s=scan(what="") 1: A 2: B 3: C 4: #여기서 엔터키 두 번 입력 Read 3 items > s [1] "A" "B" "C" |
2. 특수 자료
R에서는 몇 가지 특수한 형태의 자료를 기호로 표시한다.
| 종류 | 의미 |
| NA | 결측치 |
| NaN | 0/0 |
| Inf | 0으로 나눈 수 즉 ∞ |
| NULL | 원소가 없음 |
NA는 결측치를 표시한다.
| > x=c(1, NA, 0, 2) #두 번째 원소는 결측치 > x [1] 1 NA 0 2 |
NA와의 모든 연산 결과는 NA 이다.
| > x+1 [1] 2 NA 1 3 |
NaN은 “Not A Number”의 약자로서 0/0 및 Inf/Inf, Inf*0 등의 결과를 나타낸다. 다음은 Inf와 NaN이 발생시키고 연산한 예이다.
| > x=c(1,-1,0, Inf) > y=x/0; y #Inf와 NaN 발생 [1] Inf -Inf NaN Inf > y+1 #Inf와 NaN에 덧셈 연산 [1] Inf -Inf NaN Inf > c(1, 2, -Inf, Inf)/y #Inf와 NaN로 나눗셈 연산 [1] 0 0 NaN NaN > y*0 #Inf와 NaN에 0을 곱했을 때 [1] NaN NaN NaN NaN |
NaN의 모든 연산결과는 NaN 이며, 어떤 값을 Inf로 나누면 0 이며, Inf*0은 NaN 이다.
NULL의 의미를 이해하기 위해 다음 예제이다.
| > x=c() > x NULL > x+1 numeric(0) |
x에 어떠한 원소도 할당하지 않았다. 이러한 변수 x의 값을 NULL이라 한다. 수치 0과는 다른 개념이다.
이러한 변수와 어떤 연산을 하면 “결과의 길이가 0인 어떤 수일 것이다”라는 의미에서 “numeric(0)”을 출력한다.
3. 연산자
| 연산자 | 기능 | |
| 수치연산자 | +, -, *, / | 더하기, 빼기, 곱하기, 나누기 |
| ^ 혹은 **, %% | 거듭제곱, 나머지 | |
| 비교연산자 | <, >, <=, >= | 작다, 크다, 작거나 같다, 크거나 같다 |
| ==, != | 같다, 다르다 | |
| 논리연산자 | & 혹은 && | 논리곱 |
| | 혹은 || | 논리합 | |
| ! | 논리부정 | |
| xor(x,y) | 배타적 논리합 |
수치 연산과는 다르게 비교연산과 논리연산의 결과는 오직 “TRUE” 아니면 “FALSE” 이다.
| > 1>2 [1] FALSE > x=1:10 > 1>2 || !2*2==4 [1] FALSE > x=1;y=2; x<2 & y>=2 [1] TRUE |
4. 수치함수
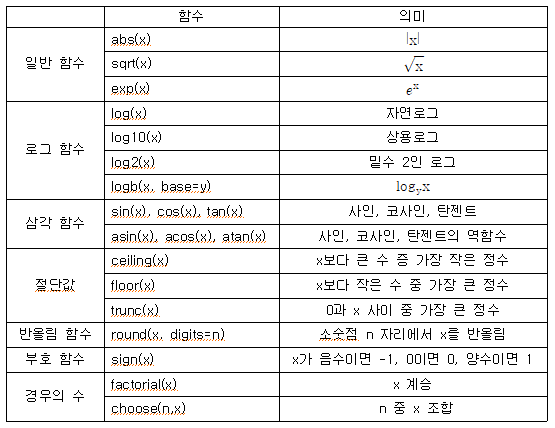

<노트> help() 혹은 ? 사용
함수에 대해 잘 모르는 경우가 있다. 이때 함수 help()나 ? 연산자를 사용한다.
예를 들어, 함수 union()의 사용법을 알고자 할 때,
> help(union)
혹은
> ?union
(RStudio에서는 검색 결과가 오른쪽 하단 “help” 탭 창에 나타남.)
5. 자료 벡터의 원소 지정과 치환
프로그래밍을 작성하다 보면, 주어진 자료 벡터의 원소들이 무엇인지 알아보거나, 참조 혹은 치환해야 하는 경우가 많다.
[1] 원소 지정
원소의 지정은 변수 옆에 대괄호를 사용하여 같은 방식으로 접근한다.
인덱싱: x[인덱스], x[ c(인덱스들) ]
슬라이싱 : x[ 시작:끝 ], x[ -인덱스 ]
한편 인덱스 앞에 “-”부호가 있으면 “해당 인덱스를 제외한 나머지”라는 의미이며, “x[]”는 x의 모든 원소를 지칭한다.
| > x=c(2, 1, 0, -1) > x[1] #x의 첫 번째 원소 [1] 2 > x[2:3] #x의 2, 3 번째 원소 [1] 1 0 > x[c(2,3)] #x의 2, 3 번째 원소 [1] 1 0 > x[c(3,1,4)] #x의 3, 1, 4 번째 원소 [1] 0 2 –1 > x[-c(2,3)] #x의 2,3 번째를 제외한 나머지 원소 [1] 2 –1 > x[] #x의 모든 원소 [1] 2 1 0 –1 |
[2] 원소 치환
x[ 인덱스 벡터 ] = 값 벡터
| > x=c(2, 1, 0, -1) > x[1]=0; x #x의 1번째 원소를 0으로 치환 [1] 0 1 0 -1 > x[c(2,3)]=c(-1,-2); x #x의 2,3번째 원소를 각각 –1, -2로 치환 [1] 0 -1 -2 -1 > x[c(3,1,4)]=c(0,1,1); x #x의 3,1,4번째 원소를 각각 0,1,1로 치환 [1] 1 -1 0 1 > x[]=2; x #x의 모든 원소를 2로 치환 [1] 2 2 2 2 |
[3] 원소의 제거
벡터의 원소를 제거하는 특별한 함수나 명령어는 없다. 그러나 음의 인덱스를 이용하여 벡터의 원소를 제거하는 기능을 할 수 있다.
x = x[ -제거하고자 하는 인덱스 벡터 ]
x = x[ TRUE 및 FALSE 값 벡터 ]
| > x=c(2,1,0,-1) > x=x[-1]; x #x의 1번째 원소 제거 [1] 1 0 -1 > x=c(2,1,0,-1) > x=x[-c(2,3)]; x #x의 2,3번째 원소 제거 [1] 2, -1 > x=c(2,1,0,-1) > x=x[c(T,F,F,T)] #x의 2,3번째 인덱스는 FALSE 나머지는 TRUE로 지정 [1] 2, -1 |
원소 지정시 True, False 대신에 T, F를 사용해도 된다.
[4]연산
연산은 원소별 연산
예를 들어 x=c(2,1,0,-1)
| > x+1 #산술 연산: 덧셈 [1] 3 2 1 0 > x-1 #산술 연산: 뺄셈 [1] 1 0 -1 -2 |
| > 2*x #산술 연산: 곱셈 [1] 4 2 0 -2 > x/2 #산술 연산: 나눗셈 [1] 1.0 0.5 0.0 -0.5 > x^2 #산술 연산: 제곱 [1] 4 1 0 1 |
| > x>0 #관계 연산 [1] TRUE TRUE FALSE FALSE > x>0 & x<=1 #논리 연산 [1] FALSE TRUE FALSE FALSE |
| > log(x) #로그 함수 사용 [1] 0.6931472 0.0000000 -Inf NaN > exp(x) #지수 함수 사용 [1] 7.3890561 2.7182818 1.0000000 0.3678794 |
길이가 같은 두 자료벡터의 연산은 기본적으로 원소들끼리의 연산으로 수행된다.
x=c(0,1,1), y=c(2,-1,1)
덧셈과 뺄셈
| > x+y [1] 2 0 2 > x-y [1] -2 2 0 |
곱셈과 나눗셈
| > x*y [1] 0 -1 1 > x/y [1] 0 -1 1 |
거듭제곱: (x,y,z)^(a,b,c)=(x^a, y^b, z^c)
| > x^y [1] 0 1 1 |
[5]자료 벡터의 속성들
자료벡터의 속성은
• 자료의 유형: mode
• 길이: length
• 자료의 이름: names
두 자료벡터
x=c(x1=2, x2=1, x3=0, x4=-1, x5=3) / / a=c(a1='kim', a2='lee', a3='park', a4='choi')
| > x=c(x1=2, x2=1, x3=0, x4=-1, x5=3) > a=c(a1='kim', a2='lee', a3='park', a4='choi') > x x1 x2 x3 x4 x5 2 1 0 -1 3 > a a1 a2 a3 a4 "kim" "lee" "park" "choi" > #자료의 유형을 알아보자. > mode(x) [1] "numeric" # 수치형 자료임을 말함. > mode(a) [1] "character" # 문자형 자료임을 말함. > #벡터의 길이 즉 자료의 개수를 알아보자. > length(x) [1] 5 > length(a) [1] 4 |
| > #벡터의 원소의 이름을 알아보자. > names(x) [1] "x1" "x2" "x3" "x4" "x5" > names(a) [1] "a1" "a2" "a3" "a4" |
추천
기초 R 3
6. 행렬 [1] 자료 벡터 이용하기 길이가 같은 벡터들을 쌓거나 이어 붙여서 행렬을 만든다. • cbind: 벡터들을 이어 붙여서 행렬을 만듦. • rbind: 벡터들을 아래로 쌓아서 행렬을 만듦. cbind() 함수
dasoni1004.com
R Markdown기초
R Markdown R 마크다운 문서는 완벽하게 재현 가능하며 PDF, 워드 파일, 슬라이드쇼 등을 포함한 수십 가지 출력 형식을 지원한다. - 분석 코드보다는 분석 결과에 관심이 있을 의사결정권자와 의사
dasoni1004.com
'study > Rstudio' 카테고리의 다른 글
| R 시각화 - 1(시각화 함수) (0) | 2021.01.15 |
|---|---|
| 기초 R 4 (0) | 2021.01.14 |
| 기초 R 3 (0) | 2021.01.12 |
| 기초 R 1 (0) | 2021.01.01 |
| R Markdown기초 (0) | 2020.12.31 |



